热门关键字:
| 电路设计 单片机学习 PCB设计 电子制作 电工基础 电路基础 电子电路图 电脑技术 维修教程 手机数码 家电维修 电力技术 电气技术 |
| 电子基础 arm嵌入式 集成电路 模拟电子 电源管理 显示光电 楼宇控制 安防监控 控制电路 音响功放 单元电路 电子下载 维修资料下载 |
引 言
确定性信号的不同时刻取值一般都具有较强的相关性;而干扰噪声的随机性较强,其不同时刻取值的相关性较差,利用这一差异可以把确定性信号和干扰噪声区分开来。对于叠加了噪声的信号x(t),当其自相关函数Rx(τ)的延时τ较大时,随机噪声对Rx(τ)的贡献很小,这时的Rx(τ)主要表现x(t)中包含的确定性信号的特征,例如直流分量,周期性分量的幅度和频率等。而对于非周期性的随机噪声,当延时τ较大时,噪声项的自相关函数趋向于零,这就从噪声中把有用信号提取出来了。
利用FPGA强大的并行运算功能和其内核中丰富的存储器资源,很容易实现一些在分立元器件中难以实现的功能,例如高速的并行乘积运算,向存储器储存和调用数据等。利用这个优势可以将一些本来复杂的运算和数字逻辑大大的简化在一块芯片之中。
SoC(System on Chip)是20世纪90年代提出的概念,它是将多个功能模块集成在一块硅片上,提高芯片的集成度并减少了外设芯片的数量和相互之间在PCB上的连接,同时系统性能和功能都有很大的提高。随着FPGA芯片工艺的不断发展,设计人员在FPGA中嵌入软核处理器成为可能,Altera和Xilinx公司相继推出了SoPC(System on a Programmable Chip)的解决方案,它是指在FPGA内部嵌入包括CPU在内的各种IP组成一个完整的系统,在单片FPGA中实现一个完整得系统功能。
与SoC相比,SoPC具有更高的灵活性,FPGA的可编程特性使之可以根据需要任意定制SoPC系统;与ASIC相比,SoPC具有设计周期短,设计成本低的优势同时开发难度也大大降低。
1 相关算法的分析及系统总体设计
1.1 相关算法

式中:N为累加平均的次数;k为延时序号。因为在FPGA等数字器件中自相关计算都是建立在数字离散域基础上的。其中x(n)与x(n-k)时间的相隔即式(2)中τ的值为采样时间间隔△t乘以延时数k,τ=△tk,在数字离散处理系统中τ的取值只能为△t的整数倍。根据数字相关量化噪声导致的SNR的退化比的定义:
D=模拟相关的SNR/数字相关的SNR (5)
数字相关的SNR=6.02n+1.76(dB),
n=A/D转换器的量化位数 (6)
从上式可见,在保持模拟相关的SNR参数不变的情况下,有效地提高A/D转换器的量化位数可以很好地减小SNR的退化比。
该设计的基本算法思想是:首先将A/D(Analogeto Digital)转化得到的数字信号通过“乒乓”RAM进行缓冲,然后将数据送人乘法器中进行乘法运算,计算得到x(n)与x(n-k)的乘积,将N次乘积送入累加器相加得到 以后,乘以1/N或者除以N即可得到式(4)。其具体流程图如图1所示。
以后,乘以1/N或者除以N即可得到式(4)。其具体流程图如图1所示。
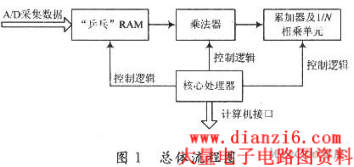
1.2 总体实现思路
相关算法整体设计思路如图2所示。
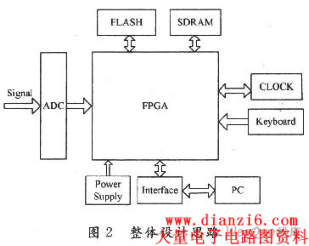
FLASH芯片 用于保存NiosⅡ中运行的程序代码和FPGA中的配置数据。在SoPC Builder中定制NiosⅡ系统时集成了CFI(通用FLASH接口)控制器。这样就可以很方便地使用FLASH芯片;SDRAM通常用于需要大量易失性存储器且成本要求高的的应用系统。SDRAM比较便宜,但需要实现刷新操作、行列管理、不同延迟和命令序列等逻辑。NiosⅡ系统中集成的SDRAM芯片接口能够处理所有的SDRAM协议要求,使SDRAM的使用方便。
CLOCK时钟模块,通过FPGA内部自带的数字锁相环将开发板上的晶振(50 MHz)提供的信号分别提供给NiosⅡ处理器和外部的SDRAM作为时钟。
Interface在该设计中为了方便地验证算法的正确,采用JTAG_UART接口实现PC和NiosⅡ系统之间的串行通信,通过在程序中调用相关驱动函数传输数据,可以在集成开发环境IDE的Console窗口中观察到运行数据。
A/D转换器采用串行12位A/D转换器ADS7822,其最高采样率位75 KS/s,将它设置为挂接在AVALON总线上的从设备,通过NiosⅡ操作系统发起询问传输获取数据。
键盘 用于用户输入信息给处理器。
在FPGA中有着丰富的存储器资源,对于验证的试验板,AItera公司提供的CycloneⅡ系列FPGA芯片EP2C20F484C8含有18 752个LE(Logic elements,逻辑单元),52个嵌入式RAM模块,35个18×18乘法器模块,4个数字锁相环,完全能实现中小规模的数字信号处理运算,在FPGA中的整体算法框图如图3所示。

2 外围处理逻辑的设计与实现
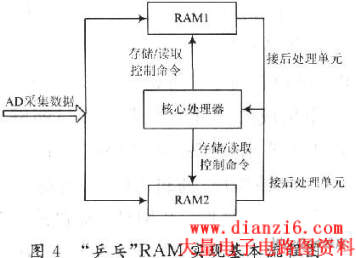
2.1 “乒乓”RAM的设计与实现
为了保持数据处理的连续性,这里采用“乒乓”RAM数据缓冲模式,即两组功能能相互切换且长度相同的RAM。它的工作原理是:其中一组RAM在进行储存操作时;另一组RAM进行读取操作,并且读取和存储的速率相同,当进行存储操作的RAM存储满,进行读取操作的RAM被清空时两者被外部控制逻辑功能互换,这样可以使两组RAM能连续不断地对A/D采集数据进行缓冲处理。如图4所示。
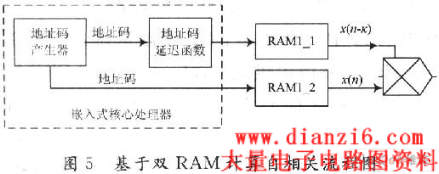
为了提高自相关计算的处理速度,每一组RAM均含有两个完全相同的RAM。在存储时存储相同的数据;在读取数据时其中一个RAM输入地址码从0开始依次读取数据形成序列x(n),另一个RAM在输入地址码加上k后读取数据形成序列x(n-k),然后将两列数列送人乘法器中进行运算完成自相关运算。这样虽然牺牲了FPGA中的存储空间,但是较之于单RAM分时读取数据的操作方式,提高了运算速率(减少2个总线读取周期)。如图5所示。
从式(4)可以看出:存储器输出的第一个数据为第一个记录数据往后延迟k个记录数据。这样就会出现一个问题:在RAM中记录的所有数据不能都用于自相关计算,当RAM1_2读取到倒数第N-1-k个数据时,RAM1_1的数据已经读取完毕,再进行计算均为无效数据(见表1)。

从表1中可以看出:在存储器中存储的N个数值中仅有N-1-k个数据进行了自相关运算,超出这个范围的数据应视为无效数据被舍弃。因此如果N的长度过短或者k的数值过大,存储器中的数据将有相当一部分数据被舍弃,并且随着k值的增加被舍弃的数据量将在整个存储数据量中的比例越来越大;但是由于信号的自相关性随着延迟k增加而降低,在做自相关运算时一般采用较小的k值。为此,如果采用较大的RAM存储器和较小的k值,在一组存储数据中舍弃的数据其实是占比例很小的。例如在k=3的情况下,即延时为3个A/D转换周期,CyclmleⅡFPGA中存储器的最大存储长度为65 536个8 b存储单元,舍弃记录数据为3个8 b,舍弃数据量仅占存储数据量的0.004%,在自相关处理时是能够接受的。如图6所示。

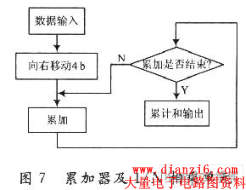
2.2 累加器及1/N相乘单元实现:
如果使用2的N阶次幂数据用作自相关计算,在二进制下可以通过向右移位N个bit位实现除法功能。在设计中采用了2×16个采样数据组成的数组完成自相关计算,其算法具体流程图如图7所示。
3 微处理器的设计实现
嵌入式微处理器的设计包括3个部分:利用SoPCBuilder定制的软核CPU,在Quartus II环境下设计的电路和Nios II编程。
Nios II的软件编程主要基于嵌入式操作系统μC/OS-Ⅱ。μC/OS-Ⅱ是一个完整的、可移植、固化和剪裁的占先式实时多任务核(Kernel)。从1992年发布至今,μC/OS-II已经有上百个的商业应用案例,在40多种处理器上成功移植。其中Altera提供对μC/OS-II的完整支持,非常容易使用。
μC/OS―II提供以下系统服务:任务管理(Task Management);事件标志(Event Flag);消息传递(Mes-sage Passing);内存管理(Memory Management);信号量(Semaphores);时间管理(Time Management)。在应用程序中,用户可以方便地使用这些系统调用实现目标功能。
在该设计中,建立了一个主任务和两个子任务(任务1,任务2):主任务主要是负责启动子任务;任务1主要负责数据的采集和采集数据的存储,任务2主要负责调用存储器中存储的采集数据控制外围计算模块进行自相关计算。总体软件算法流程图如图8所示。图9为由SoPC实现的Nios II处理器图。
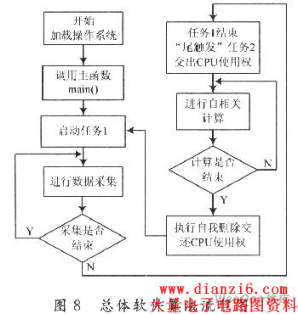

在Nios II系统中,首先,通过main()主函数调用OSTaskCreateExt()函数创建任务1,即数据采集任务。
由于AD7822作为AVALON的从外设挂接在了AVALON总线上,通过在任务1中通过调用IORD_16DIRECT()端口查询函数实时发起A从端口传输启动AD7822,获取采集数据,然后使能外围RAM的wren端口存储。当存储到该设计中存储器长度的数据以后,通过“尾触发”方式启动任务2,即自相关计算任务,并且调用延迟函数OSTimeDlyHMSM(),交出CPU的使用权。程序要点如下:

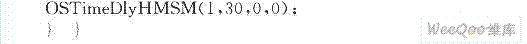
在任务2中,首先关闭两个存储器的写入使能,使之只能读出数据;然后输出相应的两个地址码:两个地址码之间有相对k的延时,并且同时使能18×18乘法器,累加器及1/N相乘单元,当循环完成后,自动删除任务2,交CPU使用权给数据采集任务。程序要点如下:

4 结 语
首先,该设计采用嵌入式操作系统实时控制外围运算逻辑电路的方式。实现了多乘加的DSP运算,由于嵌入式操作系统的灵活性和广泛的可移植性,使得该设计的可读性和移植性增强;其次,本设计采用天生并行结构的FPGA处理器完成多乘加运算,有利于提高运算速度和处理的稳定度;再次,将必要的外设作为AVALON总线器件,采用总线查询传输的方式进行访问,不必在嵌入式操作系统中过多的考虑底层硬件的驱动和时序,这样提高电路的稳定性且也增强了程序的通用性。
 温馨提示; 本站的资料全部免费下载,为方便下次找到本站记得将本站加入收藏夹哦,牢记网址http://www.dianzi6.com
温馨提示; 本站的资料全部免费下载,为方便下次找到本站记得将本站加入收藏夹哦,牢记网址http://www.dianzi6.com|
此页提供基于FPGA嵌入式的多比特自相关器设计eda技术,eda技术实用教程, EDA/PLD参考。本站还有更多的EDA/PLD相关资料分享。
Copyright© www.dianzi6.com Inc. All rights reserved 。 1 2 3 4 5 6 7 8 |
|