���Źؼ��֣�
�������㿪ʼ��ƺͿ���һ���ȶ���Ƕ��ʽϵͳͨ��������ս�ԡ������ɺ�*�������źŴ���(DSP)�㷨��ϵͳͬ���ܼ��֣���������Щ��̸���Ҳ�����ߡ���ǰ���������㷨�����ɵ����ֵ���ϵͳ�С�Ƕ��ʽϵͳ��������ʦ��β���֪���ĸ��㷨������������������������ĵ绰ϵͳ�е����������أ�
�������쵽40kHz����ƵƵ�ױ�����Ϊ����Ƶ�Ρ���������ռ��Ƶ�ĽϵͲ��֣���5Hz��7kHz��������Ƶ����ռ���µĸ�Ƶ���֣���ͼ1��ʾ��
��������������Ҫ�漰ѹ��-��ѹ����ʶ�𡢵�������ǿ�㷨���źŴ����㷨�dz�������ϵͳ��Դ��������õĴ洢����ʱ�����ܡ�������Щ��Դ������ϵͳ�ijɱ�����˲�Ʒ�ṩ��ͨ����������Щ��Դ���Խ��Ͳ�Ʒ�ɱ���һЩ�������ԣ�����洢����ʱ���������㷨�����Եı�Ȼ���֡�������Խ�ͣ��㷨Խ�ţ���ʵ�ֵĹ�Ч��Խ�ߡ�
������*��һ���㷨ʱ�������㷨�ĸ������ǵ�һ�������ض��������������㷨��Ҫ���ʱ�Ӿ����˴�����������ȡ���ڼܹ�����ͬ�Ĵ������ܹ��䴦���������б仯�ġ����㷨�Ĵ洢���������Բ���ı䡣���������DSP�㷨��һ����ֵ���д�����������һ����ֵ��Ϊһ��֡��һ����ֵ���һ��֡�����ɱ��������ӳ٣������������ӳ١����ʵ���(ITU)�涨��ÿ���㷨�Ŀɽ����ӳٱ���
�����㷨�Ĵ�������ͨ���á�ÿ�����ʱ�ӡ�����ʾ������MCPS��Ϊ�˸��õ�����MCPS�����Լ���ij���㷨��8kHz��Ƶ�ʴ���6?������֡������ÿ��֡��Ҫ300,000��ʱ�ӡ���ô�ռ�һ��֡��ʱ��Ϊ6?/8,000��8ms��ͨ�����㷨���Եó�ÿ����Դ���125��֡�����㷨�������е�֡��������ռ���ں�ÿ��300,000*125 = 37,500,000��ʱ�ӣ�����37.5MCPS��
��������һ�ֱ���MCPS�ķ�ʽ�ǣ�������(����һ��֡��Ҫ���ʱ����Բ���Ƶ���ٳ���֡��С)�ٳ���1����
����ͨ�����������㷨���������ĵڶ���������MIPS�������ָ��ÿ�롣����ij���㷨��MIPSҲ�Ƚϸ��ӡ����������ÿ��ʱ����������Ч��ִ��һ��ָ�ÿ����������MIPS��MCPS����ͬ�ġ���һ���棬����������ļܹ���Ҫ����һ��������ִ��һ��ָ���MCPS��MIPS֮�����һ�����������磬һ��ARM7TDMI������ʵ����ÿ��ָ����Ҫ1.1�����ڡ�

����ͼ1����ƵƵ��ͼ��
�����ڽ��м���֮ǰ
�������κ�Ƕ��ʽϵͳ�Ͽ�ʼ���ɺ�*���κ������㷨�����ʱ���ǵ�ϵͳ����һ����Ԥ����ȶ���״̬ʱ�����ȶ�����ζ����Ƶǰ�˵��жϽṹ��һ�µġ�����֮��������һ�����ʵķ�ֵʱ���������ᶪʧһ�������ֽڡ�ӵ�п���ϵͳ�洢����ʱ�ӵ�ͳ�������Ƿdz����ǵġ���һ�������ȶ�������ϵͳ�ϼ���һ���㷨��Խϼ����ϵͳ���ڿ����У���ͼ�����ϵͳ�ϼ��ɺ�*���κ��㷨֮ǰ��Ҫ������Ƶǰ�˽��в��ԡ����ң�Ҫ��֤��ϵͳ��û���жϷ������ͻ�����ϵͳ�д����κ����⣬�㷨�ĵ��Խ��Ƿdz�ʹ������顣
�����ڽ�Ҫ������Ƶ/�����㷨��ϵͳ�У���Ƶ�̼��������Ƚ��ģ�������Ϊ�㷨�ṩȷ�����ݲ���ʹ�㷨������Ч��ִ�С�����ʦ��������һ����������ÿ����ֵ����ʱ�ж��ںˡ�����㷨ֻ�Ƕ�һ��֡��ijЩ�̶���ֵ���д�������ô�������жϽ��Ƕ���ġ�����ͨ������ֱ�Ӵ洢����ȡ(DMA)���ڲ�FIFO��������֡�ռ���ɺ����ж��ںˡ�
����ʵ���㷨
�����������κε���ϵͳʱ������ʦͨ�����������(PCM)�������(��G.711��)�������������IJ��ԡ�����խ�������������ֵ����������8bit�ľ��ȣ�������6?kbit/s�����������������ͽ��������ܻ��ÿ��������ֵ���д���������һ�ַ�Ȩ���㷨�����ӶȺܵͣ�����û�д����ӳ٣�����ʦ����ѡ�����ñ�����������в��š���֤ϵͳ������Ҫ���dz���*����Ƶǰ����ơ�����ʦ���Լ���źŵ�ƽ������Ӳ������������棬ͬ�����˺�Զ���жϣ���֤DMA���ܣ��Լ�ʹ�����ֻ����ĵ绰���ɹ������������顣����������У�������ִ���һ�˽��յ���ѹ�������DZ��ط���ģ��벻Ҫ������֡�һ�η��������ܽ��������⡣
�����κο�����������������ǽ϶�ռ�ô洢����ʱ����Դ�������㷨��һ��ʵ�����Ӵ�ADPCM(����Ӧ����������)�㷨��������֮һ����Ӧ���� G.722������16kHz���������ݽ��д�������˸�������������Ƶ�ס���������δ������Ƶ�ʷ����D��Щ������4��7kHz�ķ����D�Ӷ��ṩ�˸���������Ȼ���������κα���������ɵ�ϵͳ֮ǰ��ǿ�ҽ���������ԡ�����G.711����ͽ�����������ֵ���в��ԣ����漰���˲�������Ƶ���㷨�ı��������������ȫ��ͬ�ģ�����Ҫ������������ǧ����ֵ���������������������֤�ù���ʦæ������ITU�������е�Ԫ���ԡ��źŵ�ƽ�����Լ����������ñ�������Ŀɻ��������ԡ�����ϵͳ���ɹ���ʦ��˵�����ڷ���֮ǰ�������������ֽڱ��16���ص����Լ��źŵ�ƽ��ʧ����صĻ��������ⶼ�����µ����⡣
�����������۵��㷨δ����ϵͳ����ʦ���ܻἯ�ɵ��㷨����Ϊ��Щ�㷨��Ҫ�����ϵͳ�洢����ʱ�����ڡ���������ǿ���㷨������ʵ���������������㷨�����������㷨�Լ�ά�ر��㷨������Щ�㷨������*�������������������������
����ͨ�����κ��漰�������������ģʽ�ĵ���ϵͳ����������ѧ�ز������㷨�����������Լ��Ļ�������������ӵĻ����в��ã�����Ҫ�������������㷨����������-��������(ECNR)��Ҫ������ϵͳ�洢����ʱ�ӡ��ж���ʱ����Ƶ����������������ѧ�������⣬���1��ʾ��
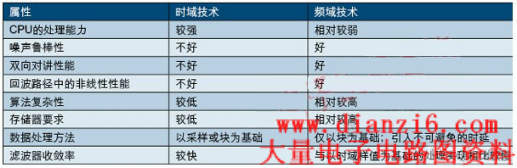
������1��ǰ�����б���Ƶ��������ʱ��������������֧��ʱ������
������ʵ֤��Ƶ������Ч����Ϊ��������ɱ��ϵ͡����ַ�����������ӦFIR�˲�������ֻ�ڵ������������������ֵʱ�Ÿ�����ϵ�����������ź��м�ȥ���ƵĻ��������������Եڶ������źű�������Щ�㷨�Ļ������ƻ�������ҪΪ�㷨�ṩ�ʵ��Ļ�����ȡ�����õĻ������ƺ�������
��������һ�������ǻ���β�����ȣ������Ժ���Ϊ��λ�Ļ�������ʱ�䡣���ԣ����ǻ����γɵ�ʱ�䡣������ȡ���ڻ�����ά�ȡ�������ϸ���˲��������һ���ܸ��ӵĻ��⣬��ѡ���˲����ij��Ȳ���̫����(����2)��
�����˲�������= ����β��������Ƶ��

������2��˵����������8kHz����ʱβ��������ز����Ǿ����Լ��˲�������Ҫ��֮��Ĺ�ϵ��
�����κλز�����(EC)ʵ�ֵĻ���Ҫ����֧�����16kHz�IJ������ݣ���ȷ���ܺ���16kHz�Ŀ�����������EC����������������������Ҫ����С�ģ���Ϊ�ز�β��ȡ���ڲ���Ƶ�ʣ�������Ϊ8kHz��������Ҫ72ms��EC������Ч������������������16kHz��������ʱ��ֻ������һ�롣��ˣ�����ʦ���ֽ�����Ч��EC������������������һ��˫����ս�Ĺ�����������������Ҳ�Ѿ�ʹ���˶��ꡣ��Բ�ͬ��Ӧ�ã�������ѡ��ʵ�ֺ�Ӧ��Ҳ��ͬ�����磬ij�ַ������ܽ�������Ϊ���������ӹ̶����㷨����������ģ�ͣ�Ȼ��������ź��м�ȥ�������������͵Ĵ�С���ֱ������������ںܶ�Ӧ����˵10��30dB��˥���ͺܲ�����
������������Ӧ���е�ECβ��Ҫ���ԼΪ50ms��Ҫ�����������ˮƽ��12��25dB֮�䣬����ȡ�������������Լ��������������������ͨ������������Խ�࣬Խ�п�����ʧ������������ˣ���̬ѡ���С�����ṩһ�����ʵ�������������ͬʱ��Ȼ�����㹻��������������������Ӧ�õ�ECNR��Ͽ�����Ҫ�ߴ�15��20kB��ϵͳ�洢����ÿ��6?����֡�Ĵ������ܺ���150,000��300,000��ʱ�ӣ���������ȡ���ڴ�������
����ECNR��ϵ�����*�����ܷdz��鷳��ͨ������ͨ������Ӳ��������������棬������˷����������λ�ã�����Զ�˺ͽ����������жϵ�ͬ�������־����������Ե���ƵӲ�������鲻ͬ��ECβ����NR��ƽ�������ѿ��ܵĻ��������������������ܡ�
������*���κ��㷨�ĸ����Ե�ͬʱ����ѧ����Ҫ��������������������Ҫ���㷨��ִ��ʱ����ڲ�ͬ��֡��˵���ܲ�ͬ����������������Դ������һ����ʵ����һ������������������нϸ߷�ֵ��ֵ�����ʱ��Ҫ�����������ֵ�ϵ���ֵ��ʱ�䳤��
��������������Ӧ�㷨��һ��ʵ���ǣ����˲�ϵ��δ������ʱ����ռ�õ����ڽ����١��˲������ݵ����������Ҫ��ǧ��ʱ�����ڣ���˺������ڷ���MCPS����ʱ����Ҫ������һ�㡣Ȼ������Ҫ�����������㷨��Ҫ���Բ�ͬ��������������ȷ��MCPS�����ܶ�����
��������λ������Ƭ���ռ�
�����������۵��㷨����ʵ�ֻ����ĵ绰ϵͳ����ϵͳ����һ��������ǿ�㷨ʱ����Ҫ���õ��㷨���л���Щ��ͬ��һЩ�����㷨���������������㷨�����ܸ�������������������ԣ���ή�������㷨�����ܡ��������㷨�������������ǿ�������̵����ִ�С�
 ��ܰ��ʾ; ��վ������ȫ��������أ�Ϊ�����´��ҵ���վ�ǵý���վ�����ղؼ�Ŷ���μ���ַhttp://www.dianzi6.com
��ܰ��ʾ; ��վ������ȫ��������أ�Ϊ�����´��ҵ���վ�ǵý���վ�����ղؼ�Ŷ���μ���ַhttp://www.dianzi6.com|
��ҳ�ṩ���������㷨�ļ������������ӵ�·����,ģ���·����, ��·�����ο�����վ���и������·����������Ϸ�����
Copyright© www.dianzi6.com Inc. All rights reserved �� 1 2 3 4 5 6 7 8 |
|